
Todos já nos sentimos um pouco perdidos quando temos que analisar dados de vendas de produtos, neste artigo irei mostrar algumas técnicas que gosto de utilizar quando me deparo com análises deste tipo.
Entenda seus dados
O mais importante para qualquer tipo de análise de dados é o entendimento do contexto daqueles dados, oque cada coluna ou campo significa. Em um mundo perfeito e hipotético, essas informações serão fornecidas para você por algum stakeholder (parte interessada, ou cliente).
Com isto em mãos, vamos então começar a analisar nossos dados.
Observação: Como os dados utilizados não são públicos, ou seja, você querido leitor não conseguirá executar os códigos abaixo, certos detalhes como importações de bibliotecas, criação de variáveis auxiliares, código para geração de gráficos, etc. Serão omitidos.
files = [
'/work/Dados/semestre_1_2020.csv',
'/work/Dados/semestre_2_2020.csv',
'/work/Dados/trimestre_1_2021.csv'
]
dataframes = [pd.read_csv(filename, sep=';').dropna(how='all') for filename in files]
df = pd.concat(dataframes, axis=0, ignore_index=True)
df.head()
df.info(memory_usage='deep')
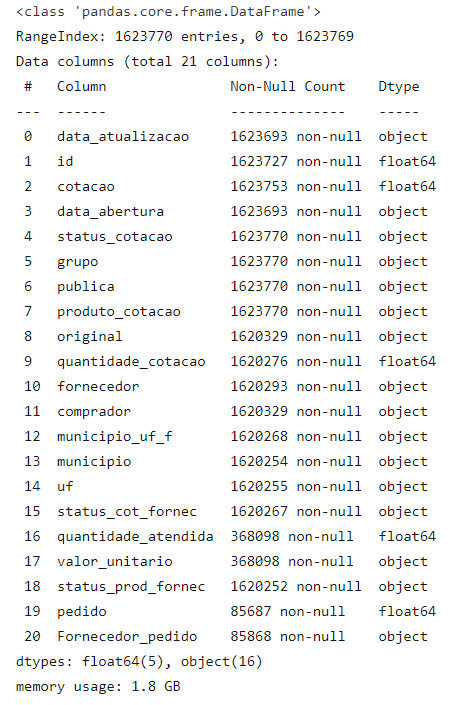
Como podemos ver acima, temos alguns problemas com a qualidade de nossos dados, vamos tratar isso.
A boa e velha limpeza de dados
Como podemos ver acima, nosso dataframe está consumindo cerca de 1,8 GB de memória, além de outras coisas:
- Colunas com números inteiros aonde o conteúdo pode ser nulo, está sendo tratado como float.
- Datas sendo interpretadas como strings.
- Colunas categóricas sendo tratadas apenas como strings, causando uso desnecessário de memória.
Vamos tratar esses fatores.
# alterando tipos de colunas para optimizar performance e memoria
df = df.astype({
'status_cotacao': 'category',
'grupo': 'category',
'publica': 'category',
'municipio': 'category',
'uf': 'category',
'status_cot_fornec': 'category',
'status_prod_fornec': 'category',
'id': 'Int64',
'cotacao': 'Int64',
})
# realizando conversao de colunas com datas
df['data_atualizacao'] = pd.to_datetime(df['data_atualizacao'], format='%d/%m/%Y %H:%M')
df['data_abertura'] = pd.to_datetime(df['data_abertura'], format='%d/%m/%Y %H:%M')
# removendo linhas invalidas/sem dados
df = df[df['id'].notna()]
df = df[df['data_abertura'].notna()]
# ordenando pela data_abertura
df.sort_values('data_abertura', inplace=True)
df.reset_index(inplace=True, drop=True)
df.head()
df.info(memory_usage='deep')
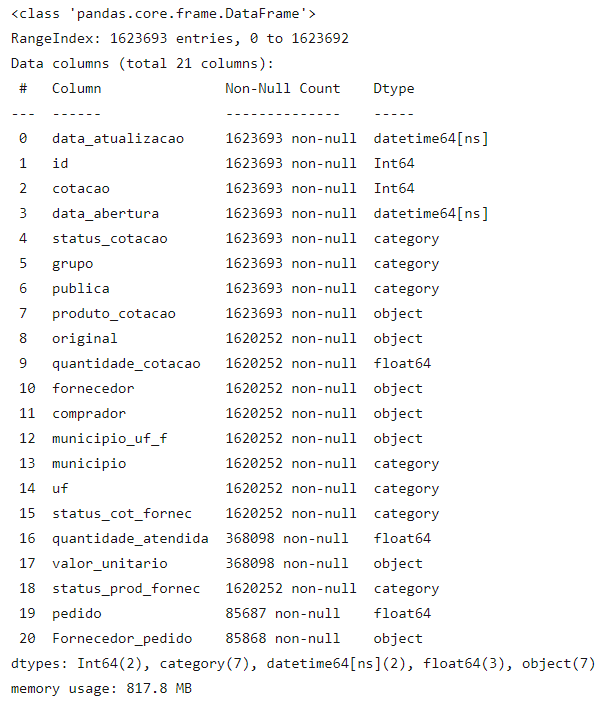
Com as alterações, além da melhora significativa de desempenho que teremos, também economizamos cerca de 1 GB de memória.
Bom, agora vamos de fato analisar nossos dados.
Grupos de produtos
Em nosso conjunto de dados temos uma coluna chamada “grupo” que indica a qual categoria aquele produto pertence, baseado nela vamos gerar alguns gráficos para quem sabe conseguir entender o comportamento de compras em nosso dataset.
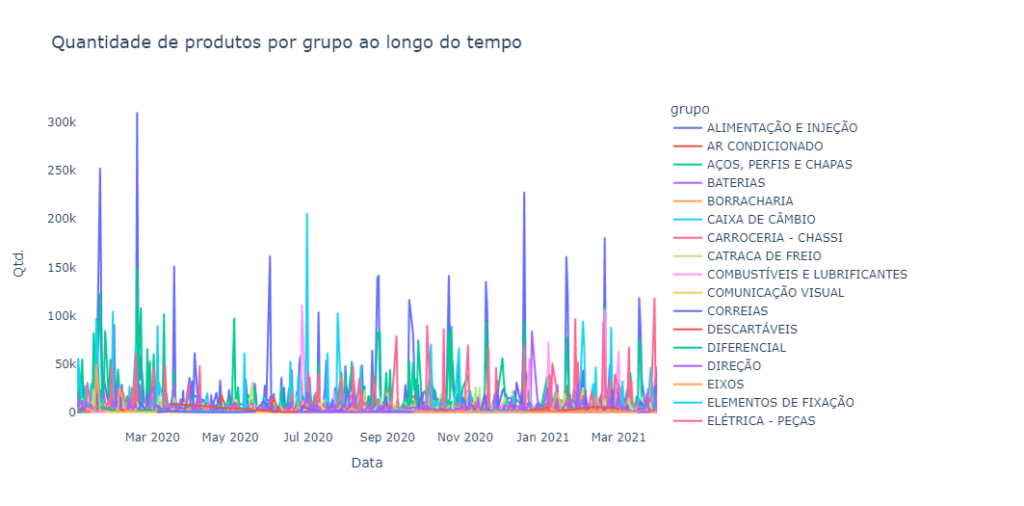
Lindo, não acha? Claro que não! Porém, mesmo com um gráfico dito “feio” podemos tirar uma série de insights:
- Primeiro, não temos uma frequência de vendas diária na grande maioria dos grupos, conseguimos notar isso graças aos visíveis picos de vendas que em alguns grupos ocorre mensalmente.
- Segundo, apesar de termos dezenas de grupos diferentes, alguns grupos aparentam ter uma quantidade de vendas maior que os outros.
- Terceiro, o grupo de “ar-condicionado” aparenta ter uma visível sazonalidade de venda ao longo do ano, provavelmente por questões climáticas (estações do ano).
Abaixo podemos ver um gráfico com os 10 grupos de produtos mais vendidos.
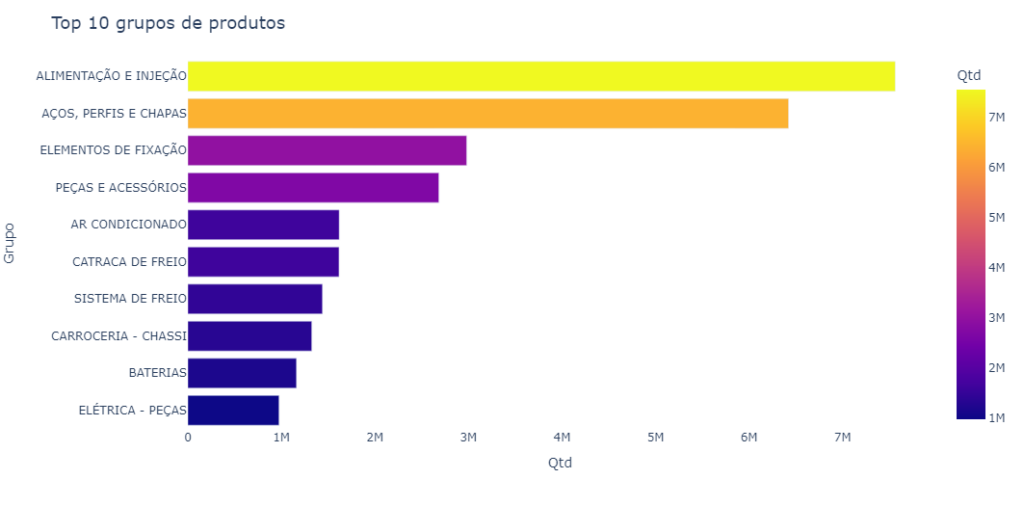
Os grupos “alimentação e injeção” e “aços, perfis e chapas” detêm a maioria da quantidade das vendas (no top 10).
Vamos dar uma olhada agora em um Heatmap da correlação entre esses grupos de produtos.
# criando serie temporal com os grupos de produtos e quantidade cotada
df_products_group_ts = df[['grupo', 'data_abertura', 'quantidade_cotacao']].copy()
df_products_group_ts['data_abertura'] = df_products_group_ts['data_abertura'].dt.date
df_products_group_ts = df_products_group_ts.groupby(['data_abertura', 'grupo'])[['quantidade_cotacao']].sum().reset_index().dropna()
df_products_group_ts.set_index('data_abertura', inplace=True, drop=False)
df_products_group_ts.sort_index()
df_products_group_ts = df_products_group_ts[df_products_group_ts['quantidade_cotacao'] > 0]
df_products_group_ts.head()
# gerando matriz de correlacoes
df_products_group_corr = df_products_group_ts.pivot('data_abertura', 'grupo', 'quantidade_cotacao').fillna(0).corr()
df_products_group_corr = df_products_group_corr * 100
mask = np.triu(np.ones_like(df_products_group_corr, dtype=bool))
rLT = df_products_group_corr.mask(mask)
fig = go.Figure(
data=go.Heatmap(
z=rLT.values,
x=rLT.columns,
y=rLT.index,
colorscale='hot_r',
name=''
)
)
fig.update_layout(
title='Heatmap de correlação dos grupos de produtos',
width=1500,
height=1500,
yaxis_autorange='reversed',
paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'
)
fig.update_traces(hovertemplate='%{x}<br>----<br>%{y}<br><br>=%{z:.2f}%')
fig.show()
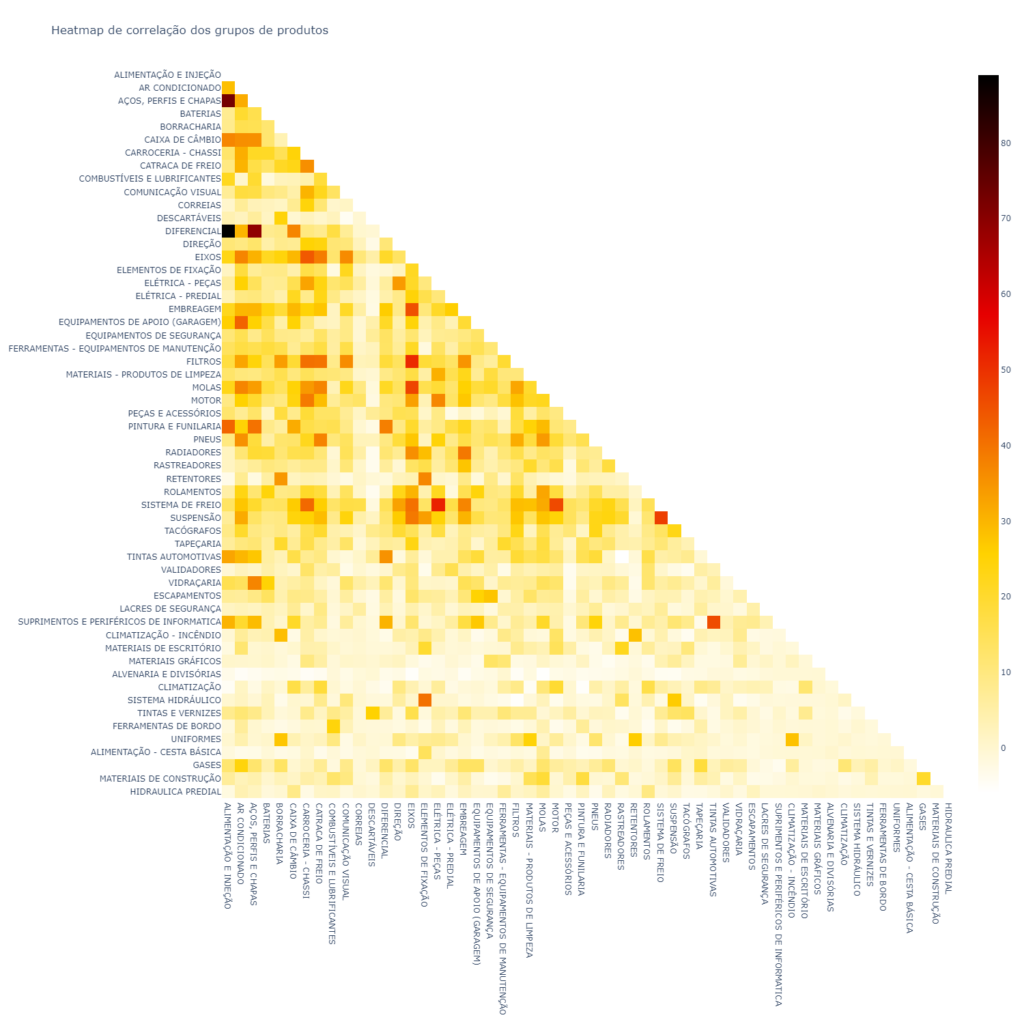
Heatmap de correlações é uma tabela mostrando os coeficientes de correlação entre variáveis. Cada célula no Heatmap mostra a correlação entre duas variáveis.
Em estatística é representado pela letra r. Formula abaixo.
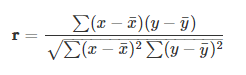
A correlação é um número que varia entre -1 e 1 (em nosso caso esse número foi transformado para valores dentre -100 e 100).
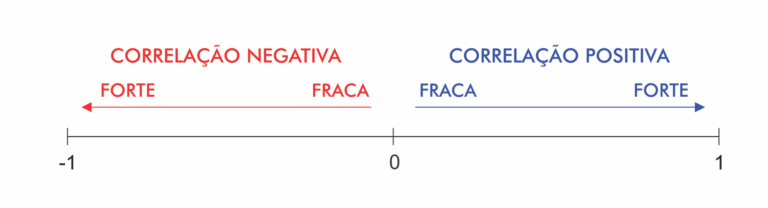
Abaixo um gráfico com as 5 maiores correlações.
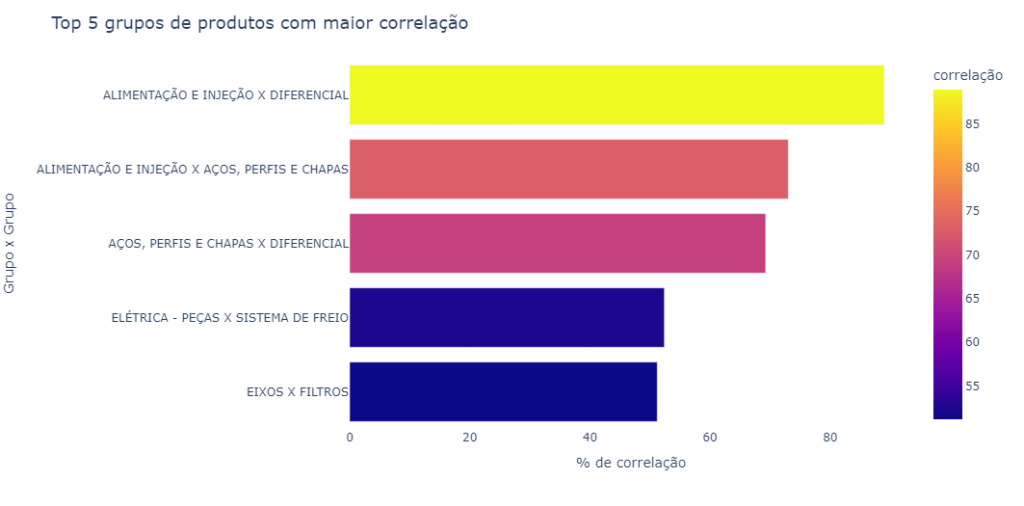
Um Heatmap de correlações é um dos meus tipos preferidos de gráficos, a partir dele conseguimos ver correlações, neste caso de vendas, que podem às vezes não ser tão óbvias, por exemplo, a correlação entre “elétrica – peças” e “sistema de freio”.
Comportamento de cotação vs dados climáticos
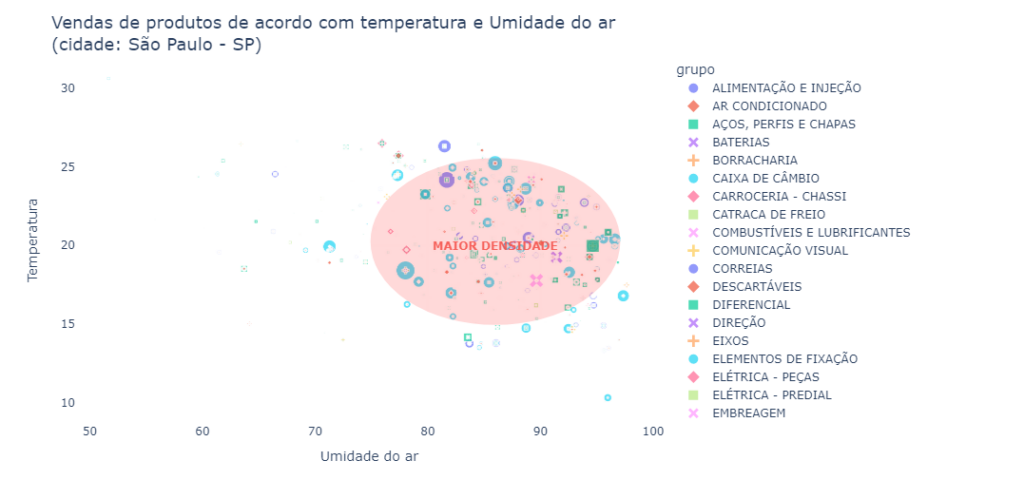
Como levantamos a hipótese de que alguns grupos de produtos teriam alguma correlação com situações climáticas, vamos então cruzar estas informações.
Foram cruzados os dados de temperatura e umidade do ar na cidade de São Paulo com as compras realizadas naquele dia, os dados de temperatura foram extraídos do site do INMET (Instituto Nacional de Meteorologia).
Abaixo você pode ver um gráfico com o resultado.
Prevendo comportamento de compra
Baseado nas análises anteriores, as vendas do grupo “ar-condicionado” aparentam ter certa sazonalidade, vamos tentar criar um modelo para prever as vendas deste grupo de produtos nos próximos meses.
date_end = datetime.date(2021, 1, 1)
df_air_conditioning_group_SP_ts = (
df_products_group_SP_ts
.query('grupo == "AR CONDICIONADO"')
.rename(columns={'data_abertura': 'ds'})
)
# suavizando os dados aplicando média movel de 7 dias
df_air_conditioning_group_SP_ts['y'] = df_air_conditioning_group_SP_ts['quantidade_cotacao'].rolling(7).mean()
# usando o facebook prophet para fazer previsão da série temporal
prophet_model = Prophet(
yearly_seasonality=True,
daily_seasonality=True,
).fit(df_air_conditioning_group_SP_ts.query('ds < @date_end'))
# realizando previsão
future = prophet_model.make_future_dataframe(periods=90)
forecast = prophet_model.predict(future)
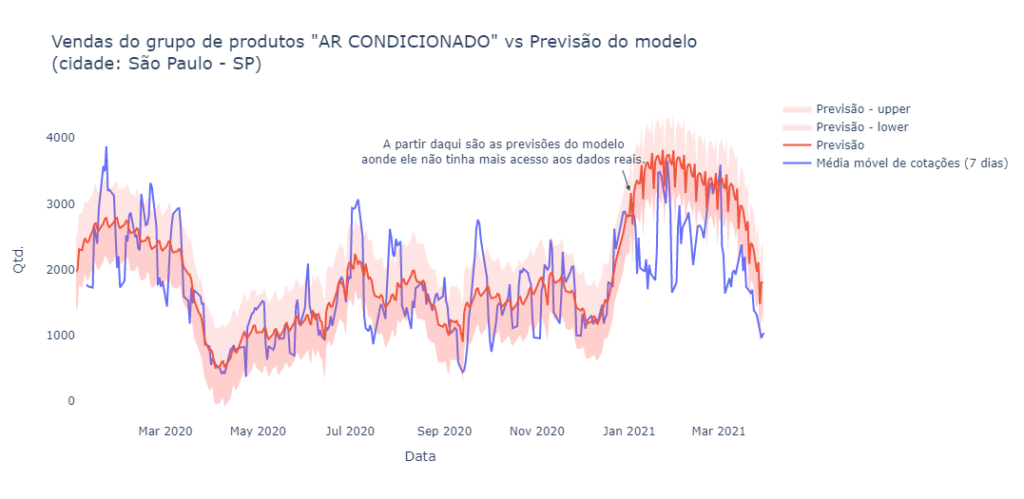
Incrível, apesar de não estar perfeito, o modelo aparentemente conseguiu identificar e prever corretamente a sazonalidade dos dados.
Abaixo estão algumas sazonalidades e tendencias identificadas pelo modelo.
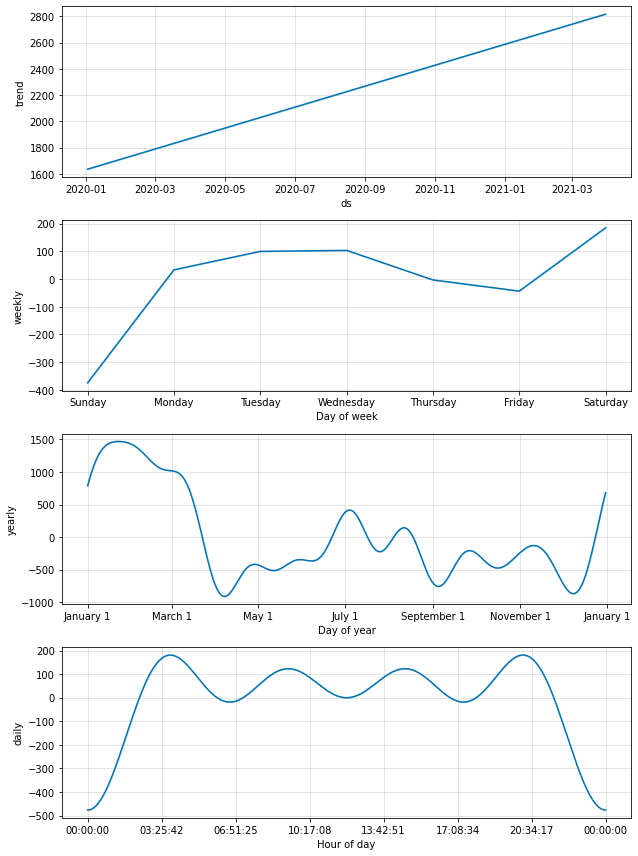
Com base nos gráficos acima podemos tirar alguns insights bem interessantes:
- A maioria das compras ocorre durante dias úteis dentre ás 3:30hrs AM e 20:30hrs PM.
- As vendas tendem a cair um pouco durante quinta-feiras e sexta-feiras e devido a está acumulação o maior pico de vendas ocorre durante os sábados.
- O dia da semana com menos vendas é domingo.
Análise de cesta de compras
Primeiramente, oque é. A análise de cesta de compras é uma técnica cujo objetivo é prever as decisões de compra dos clientes, isto é, quando o cliente compra o produto X ele também tende a comprar o produto Y junto.
Este é um tipo de análise indispensável para quando se está analisando dados de vendas, então vamos implementá-la.
df_basket = df.groupby(['cotacao', 'produto_cotacao'])['quantidade_cotacao'].sum().unstack().reset_index().fillna(0).set_index('cotacao')
df_basket = df_basket.applymap(lambda item: 0 if item <= 0 else 1)
df_fpgrowth = fpgrowth(df_basket, min_support=0.04, use_colnames=True, max_len=2)
df_fpgrowth = df_fpgrowth[df_fpgrowth['itemsets'].map(len) > 1]
df_fpgrowth['itemsets'] = df_fpgrowth['itemsets'].map(list)
df_fpgrowth.sort_values('support', ascending=False, inplace=True)
df_fpgrowth.reset_index(inplace=True, drop=True)
O support é calculado da seguinte forma:
support = transações_aonde_os_itens_aparecem / total_transações
for i, row in df_fpgrowth.iterrows():
print(f'''
Em {row["support"]*100:.2f}% das vezes em que o produto
"{row["itemsets"][0]}" foi comprado o produto
{row["itemsets"][1]}"
foi comprado junto.
''')
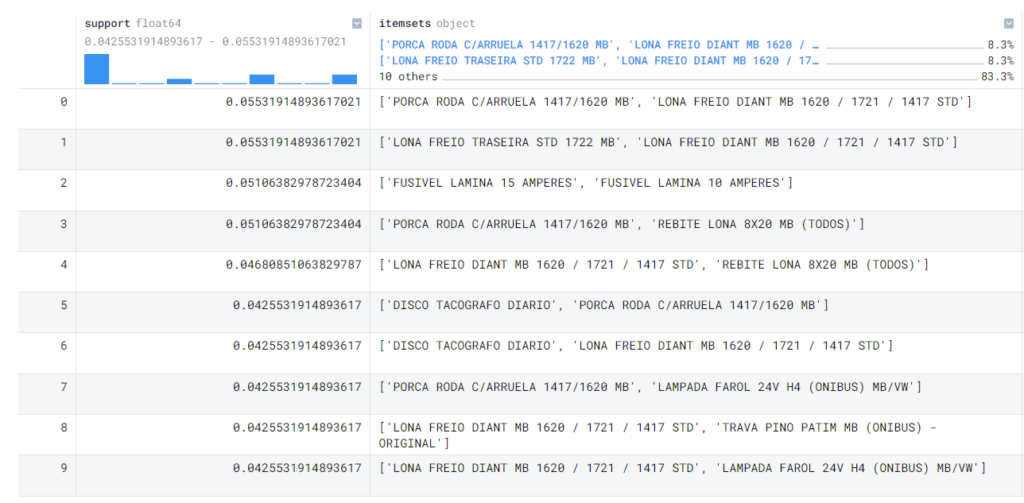
Resultados:
Em 5.53% das vezes em que o produto
“PORCA RODA C/ARRUELA 1417/1620 MB” foi comprado o produto
“LONA FREIO DIANT MB 1620 / 1721 / 1417 STD”
foi comprado junto.
Em 5.53% das vezes em que o produto
“LONA FREIO TRASEIRA STD 1722 MB” foi comprado o produto
“LONA FREIO DIANT MB 1620 / 1721 / 1417 STD”
foi comprado junto.
Em 5.11% das vezes em que o produto
“FUSIVEL LAMINA 15 AMPERES” foi comprado o produto
“FUSIVEL LAMINA 10 AMPERES”
foi comprado junto.
Em 5.11% das vezes em que o produto
“PORCA RODA C/ARRUELA 1417/1620 MB” foi comprado o produto
“REBITE LONA 8X20 MB (TODOS)”
foi comprado junto.
Em 4.68% das vezes em que o produto
“LONA FREIO DIANT MB 1620 / 1721 / 1417 STD” foi comprado o produto
“REBITE LONA 8X20 MB (TODOS)”
foi comprado junto.
Em 4.26% das vezes em que o produto
“DISCO TACOGRAFO DIARIO” foi comprado o produto
“PORCA RODA C/ARRUELA 1417/1620 MB”
foi comprado junto.
Em 4.26% das vezes em que o produto
“DISCO TACOGRAFO DIARIO” foi comprado o produto
“LONA FREIO DIANT MB 1620 / 1721 / 1417 STD”
foi comprado junto.
Em 4.26% das vezes em que o produto
“PORCA RODA C/ARRUELA 1417/1620 MB” foi comprado o produto
“LAMPADA FAROL 24V H4 (ONIBUS) MB/VW”
foi comprado junto.
Em 4.26% das vezes em que o produto
“LONA FREIO DIANT MB 1620 / 1721 / 1417 STD” foi comprado o produto
“TRAVA PINO PATIM MB (ONIBUS) – ORIGINAL”
foi comprado junto.
Em 4.26% das vezes em que o produto
“LONA FREIO DIANT MB 1620 / 1721 / 1417 STD” foi comprado o produto
“LAMPADA FAROL 24V H4 (ONIBUS) MB/VW”
foi comprado junto.
Em 4.26% das vezes em que o produto
“PORCA RODA C/ARRUELA 1417/1620 MB” foi comprado o produto
“LONA FREIO TRASEIRA STD 1722 MB”
foi comprado junto.
Em 4.26% das vezes em que o produto
“LONA FREIO TRASEIRA STD 1722 MB” foi comprado o produto
“TRAVA PINO PATIM MB (ONIBUS) – ORIGINAL”
foi comprado junto.
Assim como a análise de Heatmap a análise de cesta de compras nos proporciona uma visão sensacional sobre as correlações de vendas em nossos dados.
Conclusão
Por favor, me diga sua opinião abaixo!!!
O que achou da análise? Teria feito algo a mais ou diferente, oque?

