
Todos nos já tivemos que lidar com dados em formato JSON pelo menos alguma vez, seja utilizando uma API ou até mesmo lendo diretamente de algum arquivo e como consequência disso acredito que a maioria de nós já se deparou com erros relacionados a qualidade ou formatação dos dados contidos nele.
Neste artigo irei compartilhar duas abordagens que gosto de utilizar quando estou trabalhando com este tipo de dado em Python.
Para os nossos testes iremos utilizar a API PokéAPI.

Considere que temos a seguinte função abaixo.
import requests
def get_pokemon_from_id(pokemon_name: str) -> dict:
''' Returns all data from a givem pokemon. '''
response = requests.get(
f'https://pokeapi.co/api/v2/pokemon/{pokemon_name}/'
)
assert response.status_code == 200, 'Sheesh! 😱'
return response.json()
Alguns exemplos:
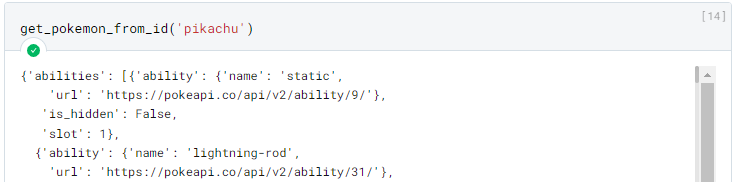
Neste caso para o Pokemon "pikachu" o resultado contém cerca de 11,200 linhas, por isso foi omitido.

Data Classes com Pydantic
A primeira é utilizando alguma biblioteca de “Data Class”, como são chamadas, existem várias bibliotecas deste tipo no Python, como, por exemplo, o modulo dataclasses (um ‘builtin’ do Python), porem a minha preferida é a biblioteca Pydantic devido a algumas funcionalidades extras que ela possui.
A documentação oficial completa dela pode ser encontrada aqui https://pypi.org/project/pydantic/.
$ pip install pydantic
Podemos instalá-la com o código acima.
Supondo que não precisamos de todos os dados da API, podemos extrair somente as informações que precisamos e garantir a qualidade delas utilizando o Pydantic.
Ele funciona baseado em classes, podemos defini-las com a seguinte sintaxe:
from pydantic import BaseModel
class Ability(BaseModel):
ability: dict
is_hidden: bool
slot: int
class Pokemon(BaseModel):
id: int
name: str
weight: int
abilities: list[Ability]
Podemos utilizá-las da seguinte forma:
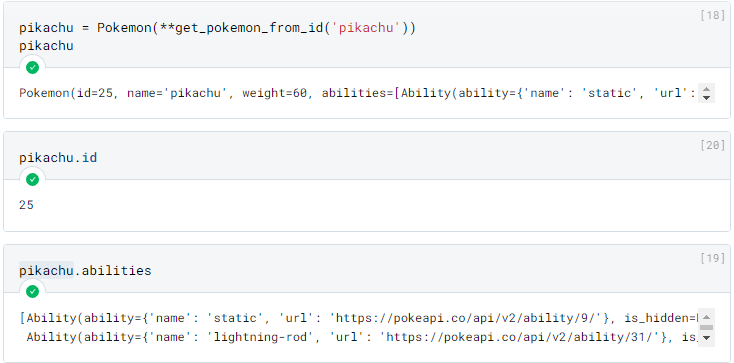
Vamos supor agora que recebemos um dado incorreto da API, o Pydantic nos notificaria da seguinte forma abaixo, com uma mensagem de erro clara e objetiva, com todos os problemas encontrados.
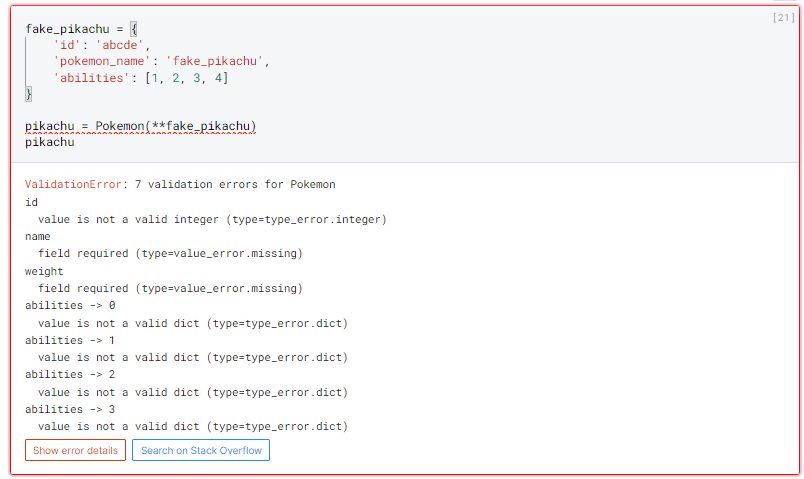
O Pydantic é incrível, porem na minha opinião ele começa a se tornar muito “trabalhoso” quando se esta trabalhando com dados muito aninhados. Veja, por exemplo, o campo “abilities”, atualmente não estamos validando seu conteúdo, apenas definimos ser um campo que contem um dicionário, caso quissemos validar o valor deste dicionario precisaríamos criar outra classe, da seguinte forma:
from pydantic import BaseModel
class Ability(BaseModel):
name: str
url: str
class Abilitys(BaseModel):
ability: Ability
is_hidden: bool
slot: int
class Pokemon(BaseModel):
id: int
name: str
weight: int
abilities: list[Abilitys]
Assim teríamos o seguinte resultado:
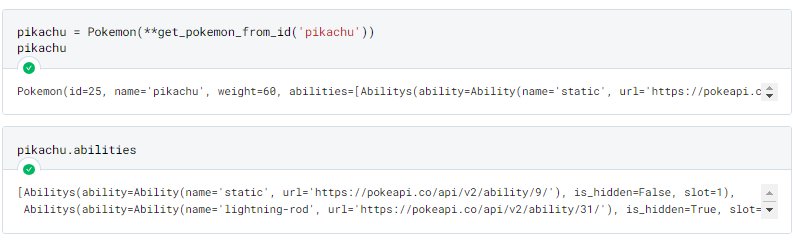
Perfeito, funcionou! Porem, conseguimos ver que quanto mais aninhado os nossos dados estiverem, mais complexo se tornara o nosso esquema de classes.
Bom, ao menos que você seja um desenvolvedor Java, eu aposto que essa ideia não lhe atrai muito, para isso em situações como estas eu gosto de utilizar outro tipo de abordagem.
Validação de Schema
A segunda abordagem é utilizando a biblioteca para definição de schemas (estruturas) chamada de “Schema”.
A documentação oficial completa dela pode ser encontrada aqui https://pypi.org/project/schema.
Podemos instalá-la com o código abaixo.
$ pip install schema
Para definir um schema utilizamos a seguinte sintaxe:
from schema import Schema
pokemon_schema = Schema(
{
'id': int,
'name': str,
'weight': int,
'abilities': [
{
'ability': {
'name': str,
'url': str,
},
'is_hidden': bool,
'slot': int,
}
]
},
ignore_extra_keys=True # Sem este parâmetro a presença de chaves adicionais ira causar o erro "SchemaWrongKeyError"
)
Assim teríamos o seguinte resultado:
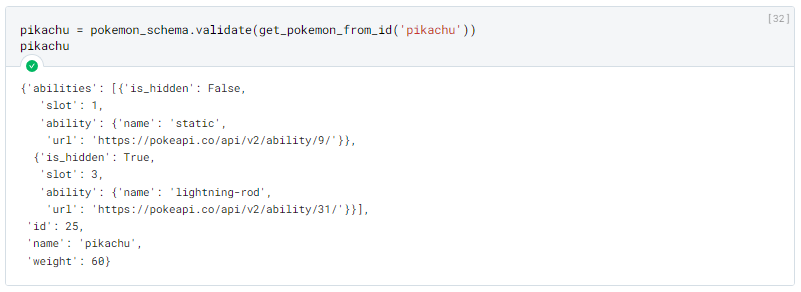
Em caso de erro de validação:
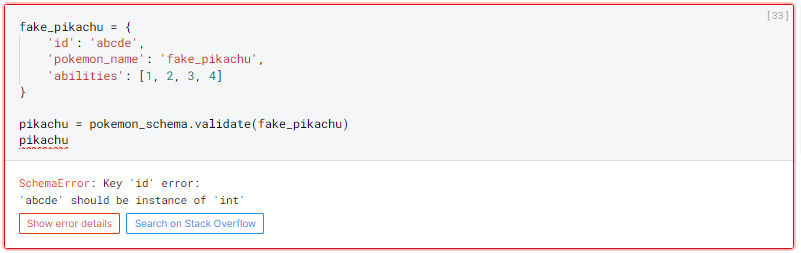
Podemos claramente ver algumas diferenças.
Primeira, o resultado da validação sera tera a mesma estrutura definida na criação do Schema (no caso do Pydantic o resultado é uma instância de uma classe do objeto definido).
A validação para no primeiro erro encontrado.
A sintaxe para definição do Schema é praticamente uma “copia” do objeto JSON, oque na minha opinião deixa muito mais legível e explicito qual sera a estrutura do objeto que terei de retorno.
Conclusão
Bom, em minha opinião, a escolha de qual biblioteca ira utilizar depende do seu contexto, por exemplo:
Caso esteja construindo uma aplicação backend acredito que a abordagem utilizando o Pydantic seja mais recomendada. Devido ao maior controle de validações que ele proporciona, e também algumas integrações existentes com ORMs.
Agora caso esteja construindo um pipeline de dados (utilizando ferramentas como Dagster, ou Airflow), onde você esta fazendo o consumo de dados de uma API ou arquivos de um Data Lake, no final do dia você só quer que seus dados estejam disponíveis em um DataFrame, então uma abordagem utilizando o Schema provavelmente sera melhor, pois não ira precisar instanciar um objeto com seus dados apenas para logo depois removê-los dela.
Por favor, me diga sua opinião abaixo!
O que achou das alternativas propostas? Qual sua preferida? Tem alguma abordagem diferente?

