Todos sabemos que garantir e validar a qualidade de dados é uma tarefa que hoje em dia ainda é extremamente trabalhosa na grande maioria dos casos, e é este problema que o Great Expectations visa resolver. Hoje vamos falar sobre essa incrível ferramenta de data quality.
Introdução
A biblioteca “Great Expectations”, feita em Python, é uma ferramenta poderosa para validação de dados. Ela permite que você defina expectativas sobre como seus dados devem se parecer e, em seguida, verifique se essas expectativas são atendidas. Isso serve para garantir a qualidade dos dados antes de prosseguir com análises ou modelagem.
A biblioteca “Great Expectations” é construída sobre o Pandas, que hoje em dia acredito que seja a ferramente mais utilizada na área de dados, isso significa que você pode facilmente integrá-lo em seus pipelines já existentes.
Para começar, vamos instalar a biblioteca “Great Expectations”. Isso pode ser feito usando o seguinte comando:
$ pip install great_expectations
Utilizando Great Expectations com dataframes Pandas
A biblioteca do Great Expectations é gigantesca, com integrações com a maioria das ferramentas e bancos de dados existentes, porem para mantermos a simplicidade neste artigo vamos utilizá-la em conjunto com Pandas.
Primeiro vamos carregar nossos dados, irei utilizar o dataset iris, pois acredito que a maioria já tenha ouvido falar sobre ele:
import great_expectations as gx
import pandas as pd
df = pd.read_csv(
'https://gist.githubusercontent.com/LucasGabrielB/6643c349374e4e67ee1f444f6da6a5bb/raw/31bde1500699da3b747ec839d06af879eb726e55/iris.csv',
)
df.head()
Agora para começar a definir nossas expectativas sobre esses dados vamos transformar esse dataframe Pandas em um dataframe do Great Expectations:
df_gx = gx.from_pandas(df)
print(type(df_gx))
df_gx.head()
* Um dataframe do Great Expectations é apenas uma abstração que utiliza um dataframe Pandas, por isso conseguimos utilizar este dataframe como se fosse um dataframe Pandas normalmente.
Agora vamos criar algumas expectativas.
# Expectativa 1: a coluna deve ter valores do tipo correto
df_gx.expect_column_values_to_be_of_type(column='sepal.length', type_='float64')
# Expectativa 2: a coluna "petal.length" deve ter valores entre 0 e 6
df_gx.expect_column_values_to_be_between(column='petal.length', min_value=0, max_value=10)
# Expectativa 3: a coluna "variety" deve apenas conter os valores "Versicolor", "Setosa" e "Virginica"
df_gx.expect_column_values_to_be_in_set(column='variety', value_set=['Versicolor', 'Setosa', 'Virginica'])
Existem centenas de expectativas distintas, recomendo dar uma olhada na documentação em https://greatexpectations.io/expectations/.
A definição de cada expectativa nos retorna um objeto chamado “ExpectationValidationResult” que contem todos os dados referente ao resultado daquela expectativa, por exemplo, este é o resultado da expectativa 2:
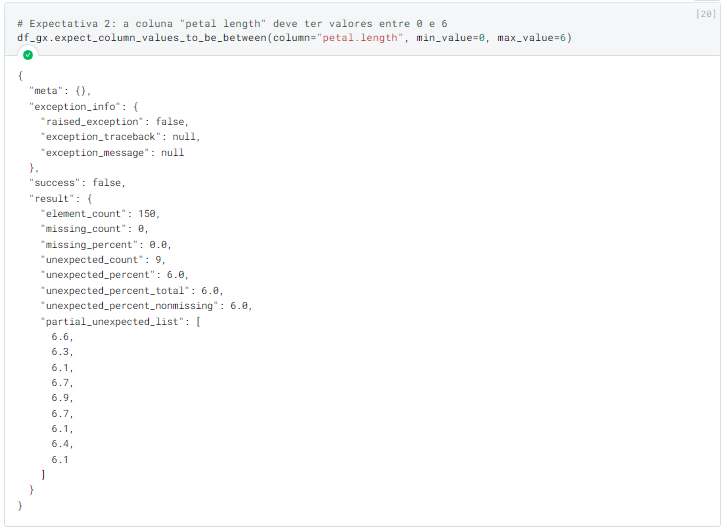
Como podemos ver, o resultado indica que a expectativa falhou (no campo “success” indica o valor “false”), e, além disso, ela também nos traz alguns detalhes do erro, como a quantidade de valores incorretos, qual porcentagem estes valores representam do total, uma amostra destes valores, e várias outras métricas que iram depender de qual foi a expectativa.
Vamos agora ajustar a nossa expectativa para que ela não falhe, mas.
# Expectativa 2: a coluna "petal length" deve ter 90% de seus valores entre 0 e 6
df_gx.expect_column_values_to_be_between(column="petal.length", min_value=0, max_value=6, mostly=0.9)

Agora, sim, nossa expectativa está sendo cumprida. Note que mesmo com um resultado positivo ainda nos é mostrado um exemplo dos valores que não cumpriram os critérios principais da expectativa.
Caso você não queira validar todas as suas expectativas uma a uma, não se preocupe, todas as expectativas são automaticamente armazenas no dataframe, você pode visualizar o resultado de todas as suas expectativas da seguinte forma:
df_gx.validate()

O método “.validate” ira retornar o resultado de todas as suas expectativas de uma vez, além de trazer todos os dados referentes ao resultado de cada uma delas.
Conclusão
A biblioteca “Great Expectations” é uma ferramenta poderosa para validação de dados em Python, além de ser extremamente simples de utilizar, com sua capacidade de definir e validar expectativas claras sobre os dados, a biblioteca permite que você mantenha a qualidade dos seus dados ao longo do tempo e evite erros futuros.
Além disso, com seu grande nível de personalização e integração, ela se encaixa perfeitamente em muitos pipelines de dados existentes e pode ser uma adição valiosa. Portanto, se você trabalha Python, recomendo fortemente dar uma olhada mais aprofundada nas capacidades dela.
Me diga nos comentários abaixo, oque você acha da ferramenta, utilizaria ela em seus pipelines, ou conhece uma ferramenta melhor?

