
Recentemente estava trabalhando na arquitetura de um novo projeto de um pipeline de dados, tudo corria bem, até que o pior pesadelo de todo o engenheiro de dados que esta trabalhando com Pandas aconteceu, meu dataset era simplesmente muito grande para ser armazenado em memória (ele continha cerca de 100 GB).
A solução para este tipo de problema já é conhecida no universo de dados (e condizente com meu contexto), clusterização! Porem uma dúvida surgiu…

Porque não utilizar logo o Apache Spark já que ele é o ‘padrão do mercado’ você pode me perguntar, bom, por alguns motivos, já bem conhecidos do Spark:
- Não é Pythonico;
- Inconsistência nas suas APIs;
- Mensagens de erro gigantescas e incompreensíveis (Java🤮);
- Você tera eventualmente que codificar algo em Scala.
Além de tudo isso, durante o desenvolvimento de nossa arquitetura atual definimos apenas uma única regra: “Qualquer ferramenta, ou solução proposta precisa ser ‘legal’ de se trabalhar com!”. Qual foi a última vez que você disse “nossa, vou subir um cluster Spark, que legal…”?
Dask
Durante minha pesquisa para substitutos do Spark, me deparei com uma biblioteca chamada Dask, basicamente Dask é uma biblioteca de computação paralela em Python, ela é dividida em dois grandes casos de uso:
Agendamento dinâmico de tarefas otimizadas para computação. Semelhante ao Dagster, Airflow, Celery ou Make, mas otimizado para cargas de trabalho computacionais interativas.
Coleções de “Big Data” como matrizes paralelas, dataframes e arrays que implementam interfaces comuns como NumPy, Pandas ou iteradores Python para ambientes para trabalhar em situações de alto consumo de memória e/ou distribuídos. Essas coleções paralelas são executadas sobre agendadores de tarefas dinâmicos.
Perfeito! Uma ferramente que nos proporciona toda a praticidade de ferramentas já conhecidas como Pandas e NumPy e sem termos que nos preocupar com detalhes de como isso tudo sera gerenciado por de baixo dos panos. Abaixo um exemplo comparando as interfaces do Pandas e do Dask.
import pandas as pd import dask.dataframe as dd
df = pd.read_csv('my-file.csv') df = dd.read_csv('my-file.csv')
df.groupby(df.user_id).value.mean() df.groupby(df.user_id).value.mean().compute()
Recomendo fortemente dar uma lida na documentação oficial do Dask, ela é super completa e rica em detalhes: https://docs.dask.org/en/stable/
Preparando o Nosso Cluster Dask Utilizando Coiled
Ainda temos um pequeno problema a resolver em nossa arquitetura, criar e gerenciar clusters é chato! Felizmente durante meus estudos sobre o Dask encontrei a solução perfeita: Coiled!
Coiled cria e gerência clusters Dask de forma 100% automática conforme as nossas especificações. Vamos a um exemplo abaixo.
Primeiro vamos instalar o pacote do Coiled e Dask.
$ pip install coiled dask[distributed]
Apos isso vamos criar um cluster com 20 maquinas, com 4 vCPUs e 16 GiB cada, totalizando 80 VCPUs e 320 GiB!
import coiled
import dask.dataframe as dd
from dask.distributed import Client
cluster = coiled.Cluster(
name='teste-coiled',
n_workers=20,
worker_vm_types=['t3.xlarge'],
)
client = Client(cluster)
Na primeira vez que criar um cluster você ira precisar informar o seu token de autenticação do Coiled, você pode consegui-lo acessando sua conta no site. Recomendo adicionar o token as suas variáveis de ambiente posteriormente para evitar esta ação manual.
Você pode criar sua conte em: https://www.coiled.io.
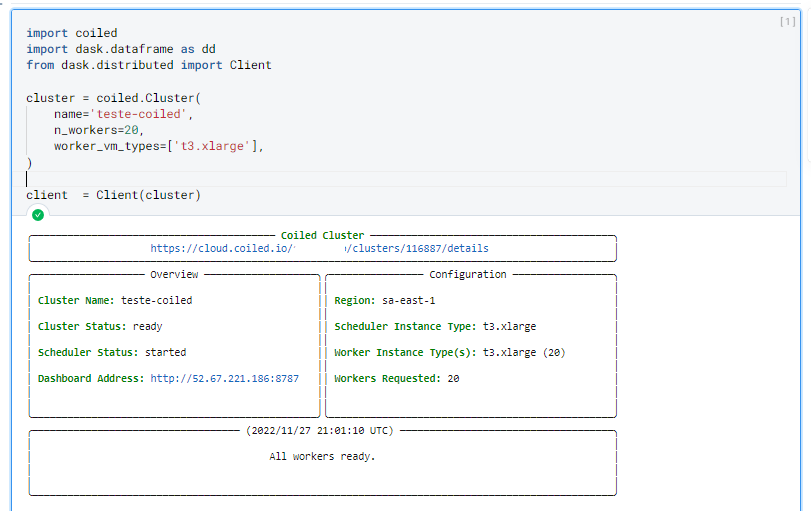
Uma vez criado seu cluster, você vera a seguinte saída indicando que tudo ocorreu corretamente:
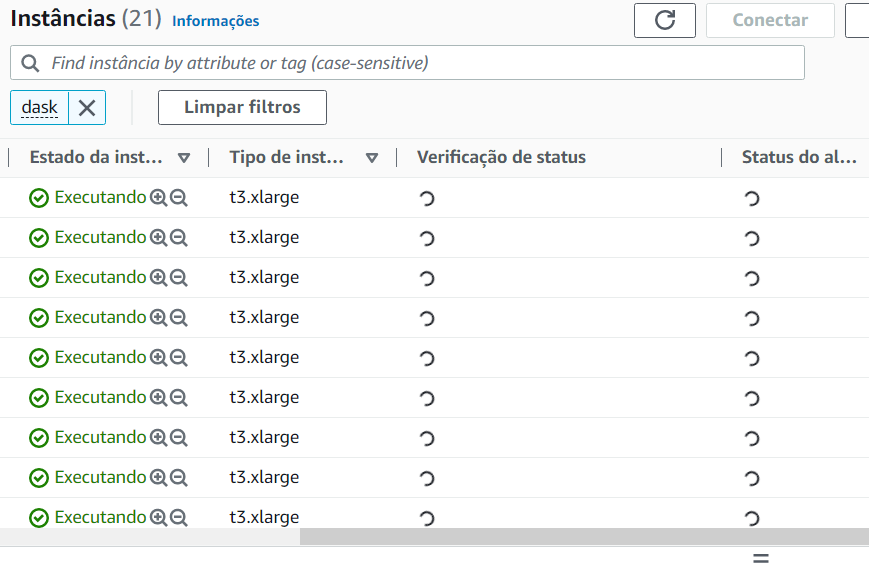
Se formos até nosso provedor cloud (nesse caso AWS) podemos ver toda a infraestrutura criada pelo Coiled.
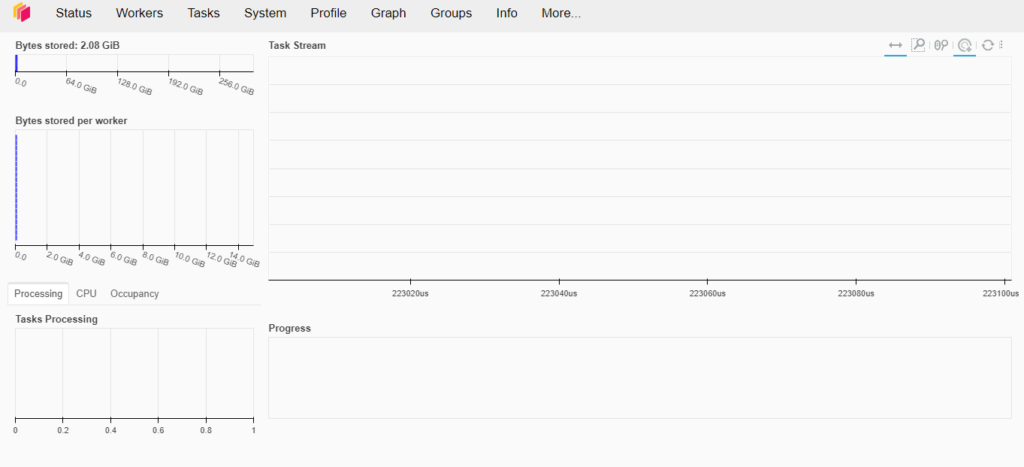
Dask também conta com uma interface gráfica aonde podemos visualizar em tempo real tudo que esta sendo executado em nosso cluster.
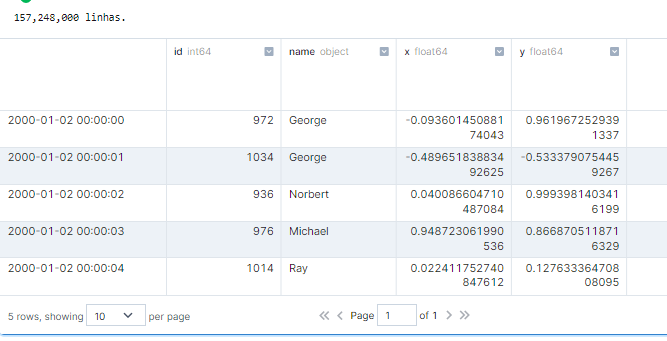
Vamos gerar um dataset de exemplo para testar os limites do Dask com o Coiled.
import dask
# gerando um serie temporal com dados aleatorios
df = dask.datasets.timeseries('2000', '2005', partition_freq='2w').persist()
print(f'{len(df):,} linhas.')
df.head()
E caso esteja se perguntando levou cerca de 500ms para executar este trecho de código. É assim que esta ação aparece em nosso dashboard:
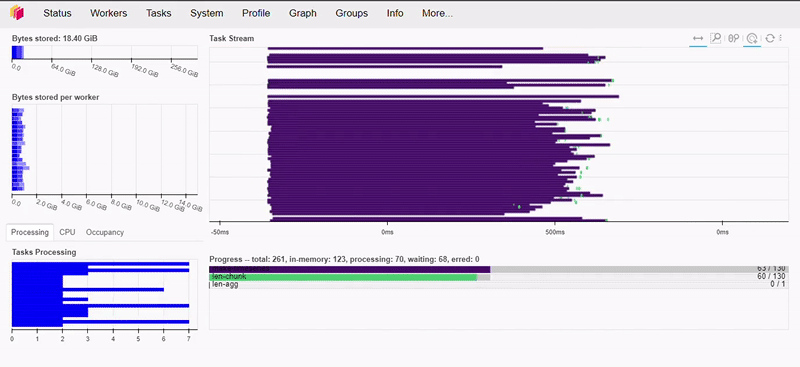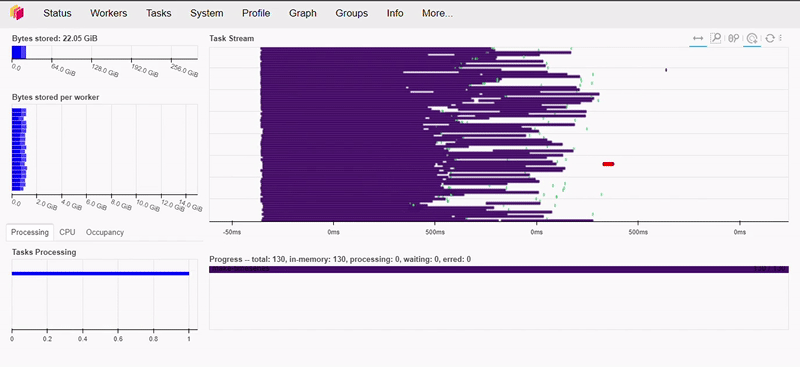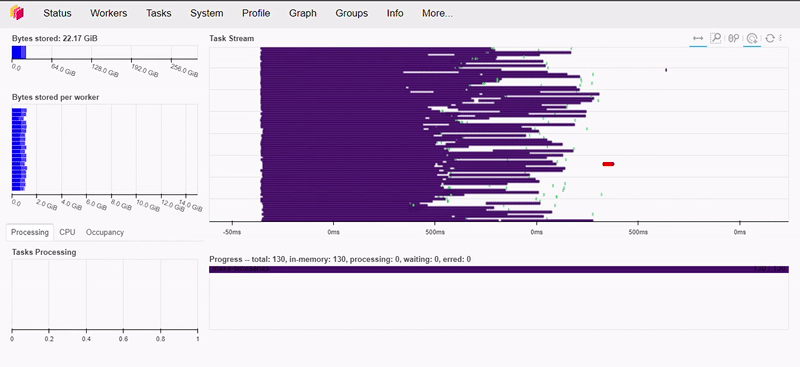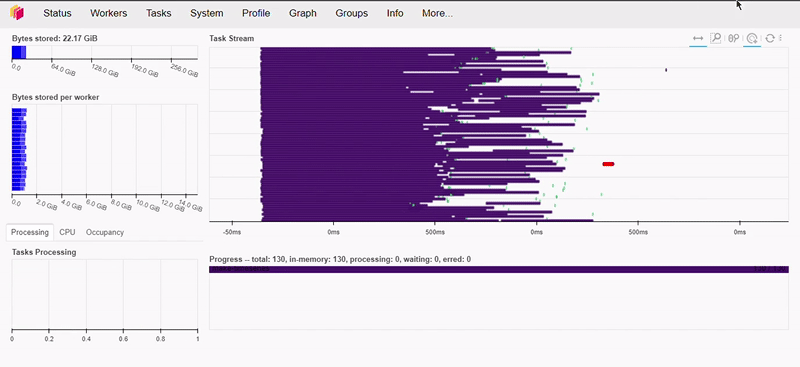
Vamos fazer uma operação mais complexa agora.
# agrupando por nome, calculando valor máximo da coluna "y" e somatória dos valores da coluna "x"
df.groupby('name').aggregate({'x': 'sum', 'y': 'max'}).compute()
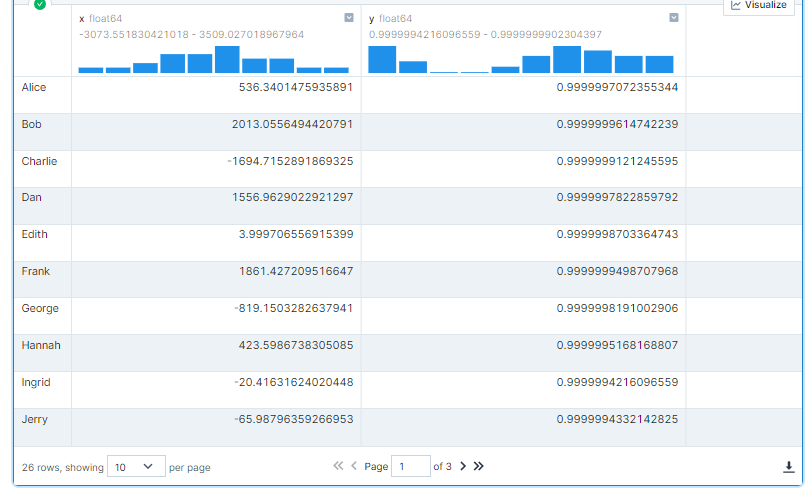
Como podemos ver abaixo, esta operação levou menos de 1 segundo para executar.
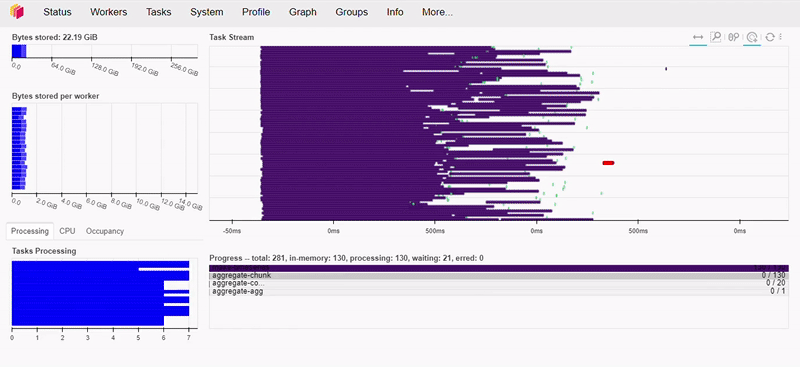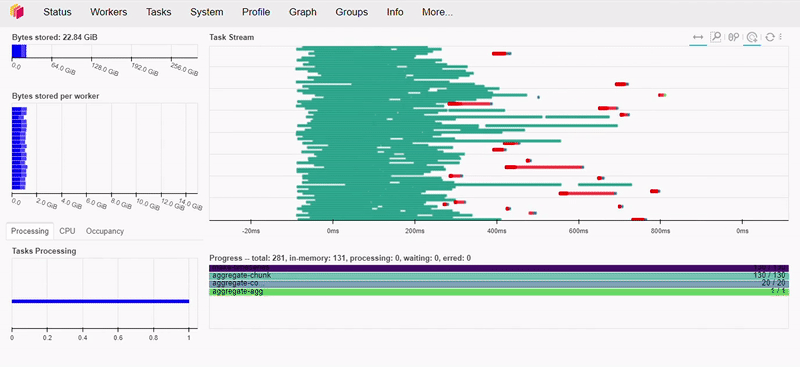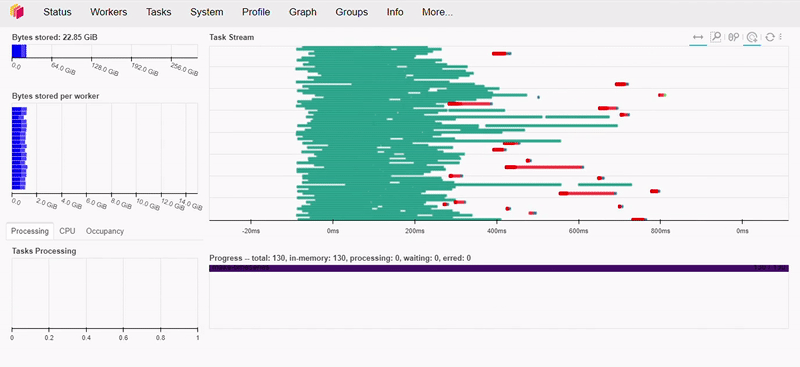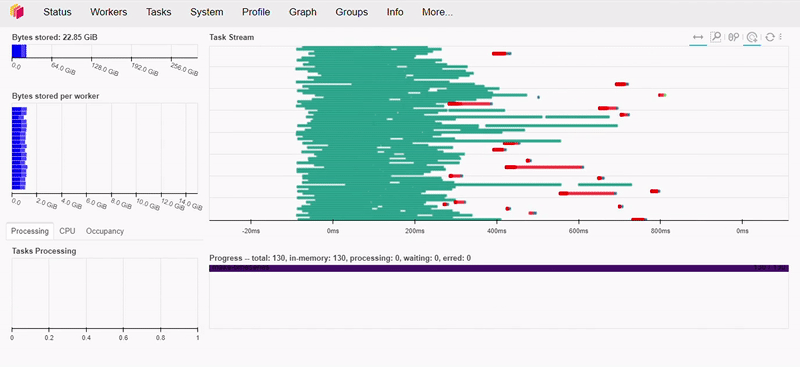
Caso esteja interessado e queira saber mais sobre a desempenho do Dask recomendo assistir a essa palestra da Irina Truong, comparando o Dask vs Spark, spoiler… Dask é mais rápido!
Para evitar surpresas no final do mês, não esqueça de desligar seu cluster executando o comando abaixo.
client.close()
cluster.close()
Conclusão
Minha experiência com Dask e Coiled foi incrível do começo ao fim, ambas interfaces são super intuitivas e muito completas, tornando assim o dia a dia trabalhando com essas ferramentas extremamente prazeroso, aonde todo o time conseguia sentir uma diferença real em produtividade. Definitivamente é muito provável que nunca mais usarei Spark!
Mas e você oque achou? Acredita que o Dask & Coiled podem te ajudar no seu contexto atual? Acredita que esse é o fim do Spark? Gostaria muito de saber sua opinião, deixe um comentário abaixo!

