No dia 9 de agosto de 2022 o Dagster finalmente anunciou o lançamento da sua versão 1.0 indicando que o orquestrador finalmente esta pronto para produção. Mas oque é Dagster? Segundo eles:
"Crie e realize o deploy de pipelines de dados com velocidade extraordinária. O orquestrador nativo da nuvem para todo o ciclo de vida de desenvolvimento, com linhagem e observabilidade integradas, um modelo de programação declarativo e a melhor testabilidade da categoria."
Promete bastante, vamos fazer uns testes com um exemplo simples. Considerando que temos o seguinte pipeline:
def get_name() -> str:
''' Returns a name '''
return 'Lucas Gabriel'
def say_hello(context, name: str):
''' Says hello to a name '''
print(f'Hello, {name}')
def my_job():
name = get_name()
say_hello(name)
Para implementarmos no Dagster precisamos fazer as seguintes alterações.
# pip install dagster dagit
from dagster import job, op
@op
def get_name() -> str:
''' Returns a name '''
return 'Lucas Gabriel'
@op
def say_hello(context, name: str):
''' Says hello to a name '''
context.log.info(f'Hello, {name}')
@job
def my_job():
name = get_name()
say_hello(name)
Dagster conta com uma interface gráfica, para acessa-la digite o seguinte comando em seu terminal:
$ dagit -f .\main.py
Agora você pode acessar o endereço http://127.0.0.1:3000 em seu navegador, aonde você vera o seguinte:
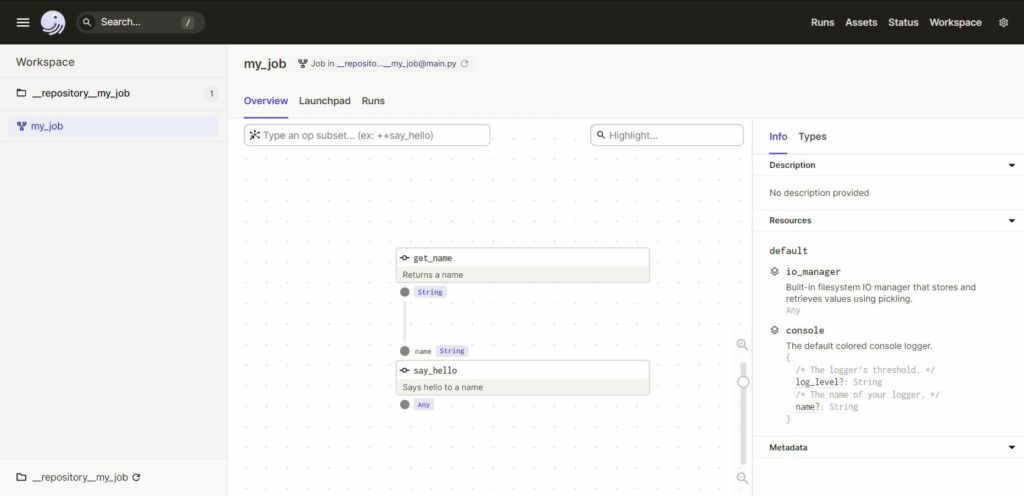
Aqui podemos visualizar todo o fluxo do nosso pipeline, executa-lo, e visualizar a documentação gerada automaticamente baseada na suas doc strings e type hints.
É isso. Com poucas linhas de código conseguimos fazer nosso pipeline funcionar no Dagster.
Para executar nosso pipeline basta clicar em “Launchpad” segundo item do menu inferior e após isso em “Launch Run” no canto inferior direito.
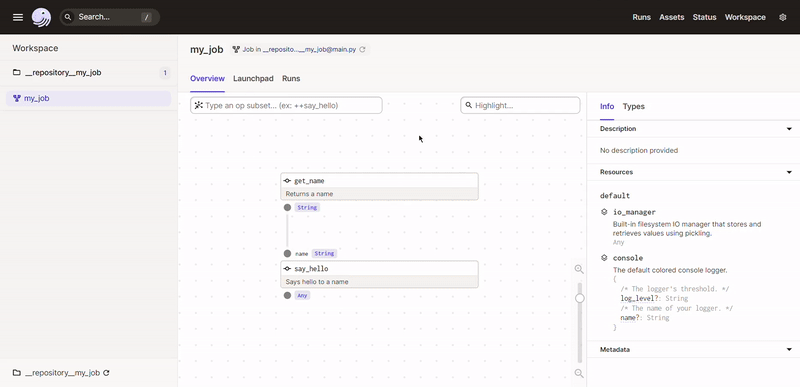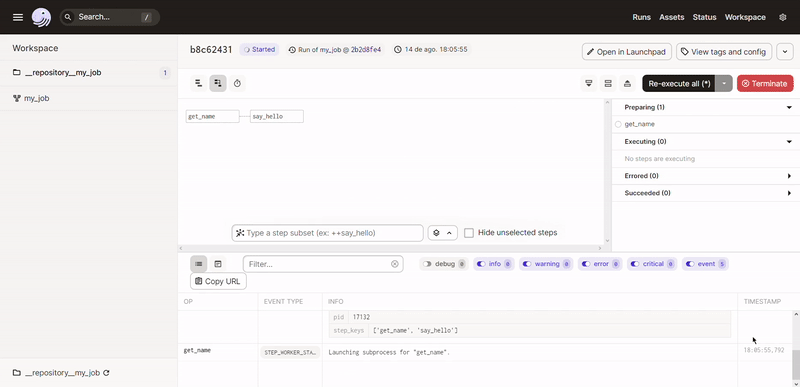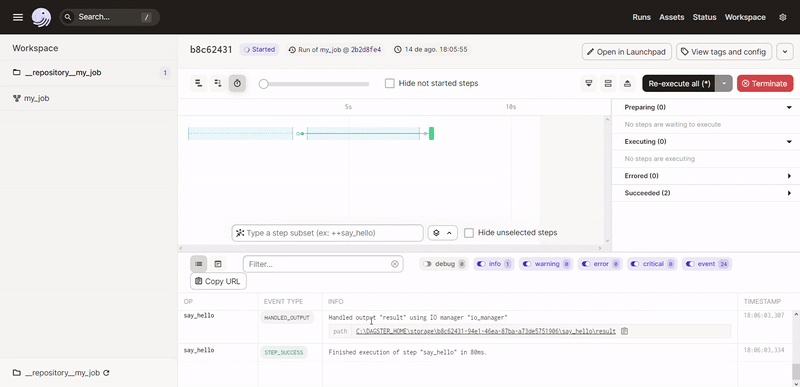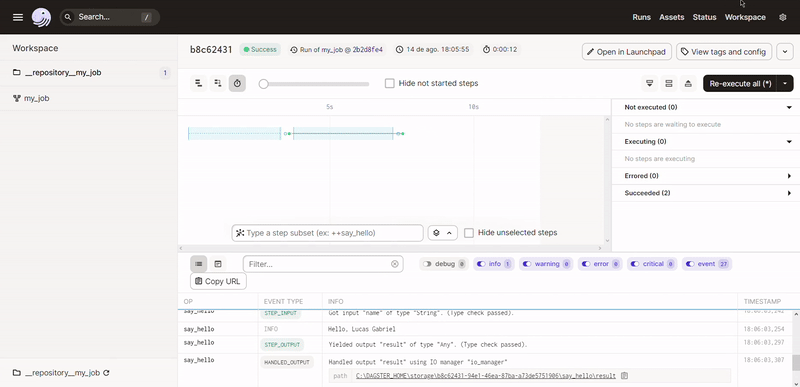
Pronto, sem precisar definir a ordem de execução das dags de forma explicita, o Dagster consegue construir todo o fluxo do nosso pipeline baseado no código contido na definição do nosso job (@job). Dentro das nossas operações (@op) podemos ter qualquer código Python arbitrário.
Mas e como agendaríamos nossas execuções? Basta fazer o seguinte:
from dagster import schedule, RunRequest
@schedule(job=my_job, cron_schedule='*/1 * * * *')
def my_scheduler():
''' Runs my_job every minute '''
return RunRequest(run_id=None)
Para trabalhar com schedulers precisamos também iniciar o Dagster Deamon, ele é o responsável por gerenciar nossos schedulers, fila de execução e algumas outras funcionalidades. Para fazermos isso basta executar o seguinte comando:
$ dagster-daemon run
Esta é uma das formas mais simples de definir um Scheduler, porem a interface do Dagster permite vários parâmetros opcionais que permitem configurar toda a sua execução.
Dagster soluciona muitos dos problemas encontrados no Airflow atualmente, como
- Testabilidade, é absurdamente fácil desenvolver testes unitários e também diferenciar entre diferentes ambientes (exemplo: Desenvolvimento e Produção).
- Organização, um dos grandes problemas do Airflow na minha opinião é a falta de uma forma fácil e intuitiva de organizar seu código, todas as suas dags ficam “juntas”, dificultando a visibilidade, já no Dagster além de poder organizar seu código em diferentes repositórios (como é chamado) você também tem a incrível funcionalidade de poder ter varias fontes diferentes do seu código, com versões do Python e bibliotecas diferentes.
- Escalabilidade, Dagster consta com uma serie de tutoriais muito completos sobre como realizar o deploy para produção, utilizando, Docker compose, Kubernets, AWS ECS, dentre outros.
- Dagster também conta com um conceito chamado de Software Defined Assets (ativos definidos via software), que é incrível, não irei comentar sobre ele pois é um assunto que merece um artigo próprio, porem definitivamente recomendo pesquisar sobre.
Dagster tem tudo para ser o novo orquestrador da stack moderna de dados, agora basta ver como o mercado e a comunidade ira absorve-lo.